
Toward Active-Inference in Radiology: Teaching AI to Refine Its Beliefs

Most AI radiology systems act like overconfident students: they give one answer and never reconsider.
But human radiologists work differently. They reason under uncertainty, update their beliefs, and sometimes defer. Can we build AI that does the same?
Why current AI isn’t enough for medicine
Modern deep learning has brought impressive results in medical imaging. Models trained on large chest X-ray datasets can detect pneumonia, lung nodules, or cardiomegaly with high accuracy.
But here is the catch:
They usually give one-shot predictions.
Their confidence scores are often misleading.
They cannot explain how their belief changes with new evidence.
Radiologists, by contrast, constantly refine. They notice a possible opacity, reconsider after looking at another view, and sometimes say: “I’m not sure — this needs escalation.”
This is where the idea of active inference comes in: a framework in neuroscience that views perception as the process of minimizing prediction error over time. Instead of a static answer, the system keeps updating until its uncertainty is reduced.
The roadmap
To explore this idea, I built a staged pipeline:
Step A — Baseline CNN: a standard ResNet18 for pneumonia detection.
Step B — Ensembles + Calibration: multiple models whose disagreements reveal epistemic uncertainty.
Step C — Selective Prediction (Triage): the model abstains on uncertain cases.
Step D — Predictive Generative Model with Iterative Refinement: a VAE-like backbone that improves predictions step by step.

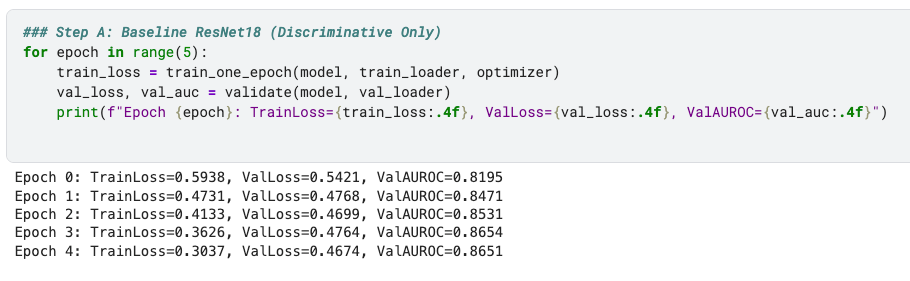
Step A: Baseline CNN
I started with ResNet18 trained on the RSNA Pneumonia dataset. This gave:
Validation AUROC ~0.86 after 5 epochs.
Stable training/validation losses.
This is the kind of performance you’d expect from a decent one-shot classifier.
Step B: Ensembles and Calibration
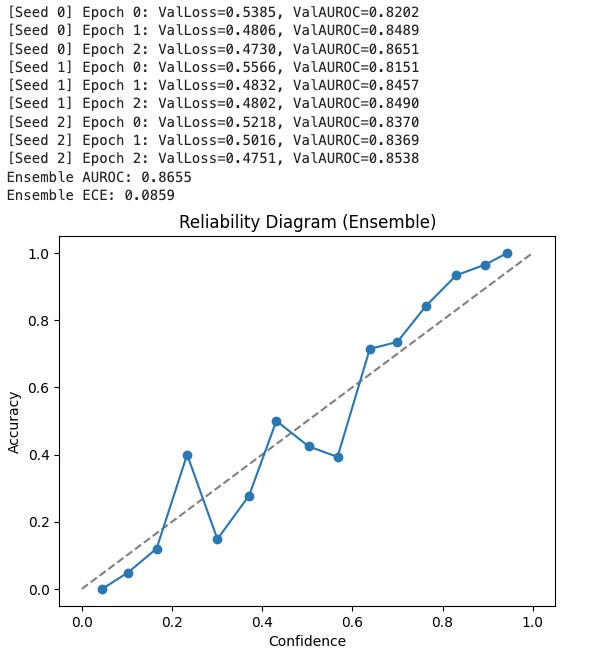
Next, I trained three ResNet18 models with different random seeds. Averaging their predictions:
AUROC climbed slightly (~0.864).
Expected Calibration Error (ECE) dropped to ~0.088.
Reliability diagram: predicted confidence closely matched actual accuracy — curve tracks the diagonal, showing well-calibrated probabilities.
The ensemble gave not only better performance but also uncertainty estimates: the variance across models tells us how much the system “knows what it doesn’t know.”
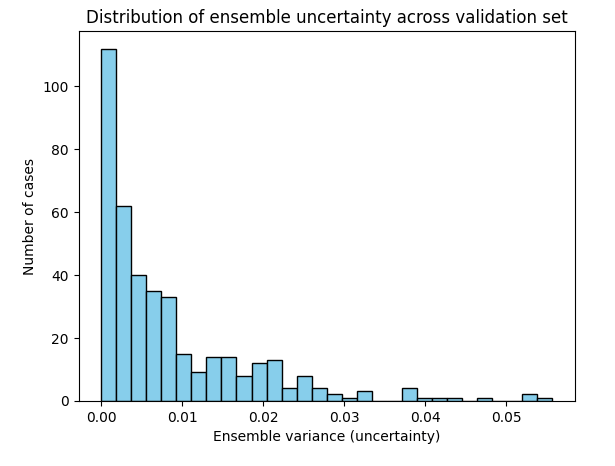
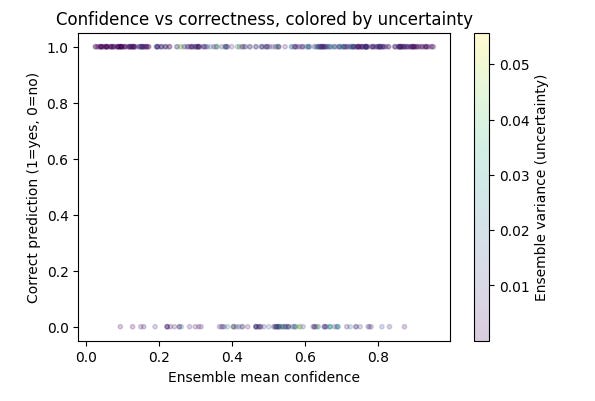
The ensemble’s uncertainty behavior matched intuition. As shown in the distribution plot, most chest X-rays had near-zero variance across models, reflecting strong agreement. But a subset of cases produced higher variance, signaling genuine uncertainty. The scatter plot confirms this: correct predictions were made with high confidence and low variance, while errors clustered at lower confidence with more disagreement. In other words, the ensemble not only improved accuracy but also flagged the cases it was least sure about which is a critical step toward radiologist-like reasoning.
For reference, Deep ensembles are widely regarded as the most practical way to capture epistemic uncertainty. That is the uncertainty that arises from limited data or model capacity. By averaging predictions from independently trained models and measuring their disagreement, ensembles reliably signal when the system “doesn’t know” [Lakshminarayanan et al., 2017; Ovadia et al., 2019].
Step C: Selective Prediction (Triage)
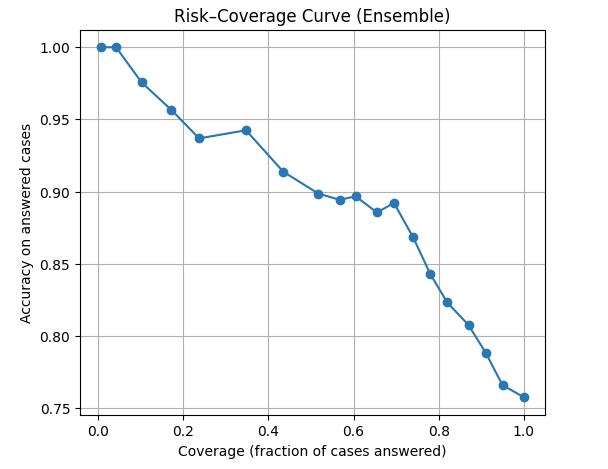
With calibrated confidence, the model can actually abstain (It knows when to say it does not know). When I plotted a risk–coverage curve, the result was as follow:
At 100% coverage, accuracy is around 0.76 (all cases).
At ~50% coverage, accuracy jumps above 0.9.
On the most confident ~10% of cases, accuracy approaches 1.0.
This mimics how radiologists behave: they report confidently when sure, and defer ambiguous cases to ask for second opinion or review carefully.
Step D — Predictive Generative Model with Refinement
Up to this point, our models were all discriminative: they looked at an X-ray and output a probability of pneumonia. That works, but it’s a one-shot guess.
Humans don’t work that way. Radiologists revise their impressions as they look closer. To capture that behavior, I tried something different: a generative model that learns by reducing its prediction error step by step.
Here’s how it works:
First guess: The encoder looks at the input X-ray and produces a compressed latent description — its “first impression.” From this, the classifier outputs an initial pneumonia probability.
Prediction error: The decoder tries to reconstruct the original X-ray from that latent description. The mismatch between the reconstruction and the real image is the model’s prediction error.
Refinement: The model uses that error signal to adjust its latent representation and then re-predicts. With each step, the reconstruction improves, the error decreases, and the classifier becomes more stable.
Belief updating: After a few refinement steps, the model has updated its “beliefs” about the image enough that prediction error is minimized and the pneumonia probability is more reliable.
How I built it:
I adapted a variational autoencoder (VAE) as the backbone. The encoder turned each X-ray into a latent distribution (mean and variance).
From this latent space, two things happened: (1) the classifier predicted pneumonia, and (2) the decoder tried to reconstruct the input X-ray. Training optimized all three objectives at once: reconstruction loss, KL divergence (to regularize the latent space), and classification loss.
To mimic refinement, I didn’t stop after the encoder’s first output. Instead, I let the model run for several inference steps: at each step the latent state was updated using its prediction error, then passed again through the classifier and decoder. This gave us a sequence of predictions that could be directly compared.
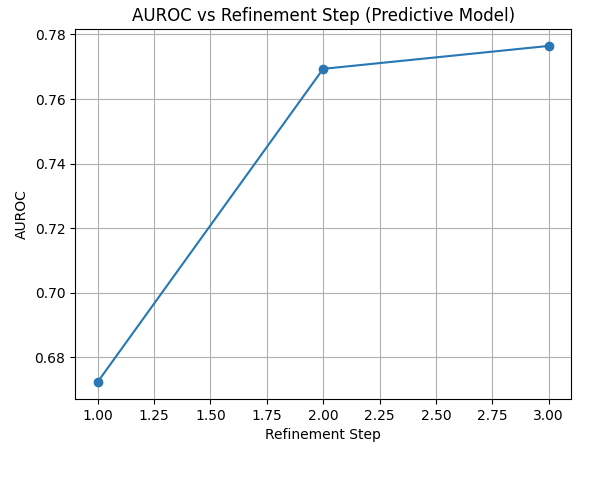
What we saw:
At the first step, AUROC was about 0.67 — a weak first impression.
By the second step, AUROC jumped to 0.77.
By the third step, it stabilized around 0.78.
That upward trend is exactly what we hoped for: the system learned by reducing prediction error, refining its belief about the image just as an active-inference framework predicts.
While ensembles, step B, captured epistemic uncertainty through model disagreement, our predictive generative model begins to address aleatoric uncertainty which is the inherent ambiguity in the image itself. By reconstructing the X-ray and refining its latent representation step by step, the model explicitly reduces prediction error, offering a pathway to combine both epistemic and aleatoric signals in a single, active-inference–style framework.

Why this matters
This prototype shows that medical AI doesn’t have to be a black box that outputs one answer. Instead, it can:
Quantify uncertainty (ensembles, calibration).
Decide when not to decide (selective prediction).
Refine its beliefs iteratively (generative active inference).
These features are exactly what radiologists do in practice. An AI with these capabilities could become a more trustworthy collaborator, not just a static tool that hallucinates or generates poorly.
Limitations
This tutorial is a brief proof of concept, not a finished diagnostic tool. Several important limitations are worth noting.
First, I only trained on a small balanced subset n = 4000 of the RSNA dataset and for only 3 epochs. The models are deliberately simple, so performance lags behind state-of-the-art systems trained on much larger datasets like CheXpert or MIMIC.
Second, the predictive generative model is still minimal. The decoder and latent space are crude, and the refinement loop does not yet implement a full free-energy gradient update — it just demonstrates the principle. This makes the AUROC lower than the discriminative baseline, even though the trend across steps is encouraging.
Third, the evaluation is limited. I only tested on one dataset, without exploring robustness to distribution shifts, external cohorts, or out-of-distribution detection. I also haven’t compared the outputs with radiologists in a reader study, so we don’t yet know whether the uncertainty estimates and refinement dynamics are actually helpful in practice.
Finally, while the system can abstain and refine its beliefs, it still lacks clinician-facing explanations. I haven’t integrated concept-level reasoning or tested how the outputs might fit into a real workflow.
What is next?
This is only a proof of concept. Accuracy is lower than state-of-the-art, and training was short. But it opens a path:
Train on larger datasets like CheXpert or MIMIC-CXR.
Add concept-level explanations (e.g., “opacity,” “cardiomegaly”) to make refinement interpretable.
Combine uncertainty and refinement dynamics into decision support dashboards.
Test with radiologists: does an AI that shows confidence + iterative improvement make them more likely to trust it?
Closing
Taken together, these four steps show a progression from a conventional classifier to a more radiologist-like reasoning system. The baseline CNN (Step A) delivered solid accuracy but no real sense of confidence. Ensembles (Step B) added calibrated probabilities and epistemic uncertainty, while selective prediction (Step C) demonstrated how uncertainty can be used to triage difficult cases. Finally, the predictive generative model (Step D) showed that beliefs can be refined iteratively, with AUROC improving step by step as prediction error is reduced. The result is not a production-ready system, but a proof of concept: AI in radiology can move beyond one-shot classification toward uncertainty-aware, self-reflective reasoning.
👉 This post builds upon concepts I published in a preprint titled: A Path Towards Autonomous Machine Intelligence in Medicine